This site uses advanced css techniques
Stopping and starting of Evolution services is a routine part of running an Evolution instance, and this Evo Tip means to spell out some best practices for managing them.
These practices are driven by a desire to avoid a poor experience for the Evolution users who this gear is here to support, all based on experience in multiple environments.
Note: This Tip is intended only for IT staff who actively administer an Evolution environment: if you are a service bureau hosted on any SaaS environment, Asure staff handles this for you.
Services are typically managed by the Evolution Management Console, a service that itself is managed with a web browser. Many configuration and monitoring operations are available, but we're looking at only a few of them. This is not a comprehensive guide to the Evo Management Console.
We mainly focus on the Service Control page, available from the Maintenance tab on the left:
All services are listed, including their running status, and with obvious start and stop options.
However: Never use the [Restart] option, ever, for any reason.
Though conceptually a restart should be the same as a Stop followed by a Start, the Windows services API provides an explicit "Restart" interface that Evolution appears not to implement correctly. Sometimes a restart will work, other times it won't, and failure is not immediately apparent to the administrator (the service will run, but Evolution won't work correctly).
Many, many years of experience have made it clear: never, ever use [Restart]. We have requested that this option be removed from the Evo Mgmt Console interface to avoid confusion.
Stopping services is necessary before a routine update as well as routine Windows maintenance, and this is straightforward by just clicking the [Stop] on All Services in the upper left of the right pane:
When clicking [Stop], the Evo Management Console sends a request to the Deployment Manager service on every machine asking it to stop all the Evo services, and it waits for all to stop before returning.
This process can take some time, and occassionally a service will get stuck while stopping, needing a bit of help. This is particularly the case with Remote Relay, which often takes quite a long time due to what I believe is a bug.
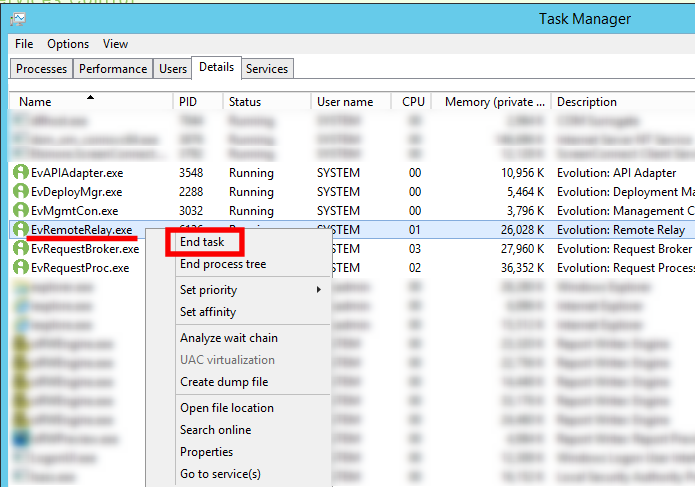
In this case, you can manually kill Remote Relay via the Windows Task Manager; this must be done from the machine hosting the service itself (and some Evo instances have more than one Remote Relay, each installed on a different middle tier Windows machine):
This is common enough that when I'm stopping all services while doing customer maintenance, I immediately go to the task manager and kill RR, not waiting to see if it will stop on its own. On the classic SaaS platform, the orchestration for pod management kills Remote Relay as part of the process as well.
We don't know why Remote Relay hangs in spite of a fair effort of research.
Also note that the Evo MC occasionally misrepresents service status: even after all services have genuinely stopped, it may still show them "running" with the green check. Just re-click the "Service Control" tab on the left to refresh the status.
Unlike stopping, which you can do in one shot, starting is a bit more complicated due to the requirement that services all be started in a particular order.
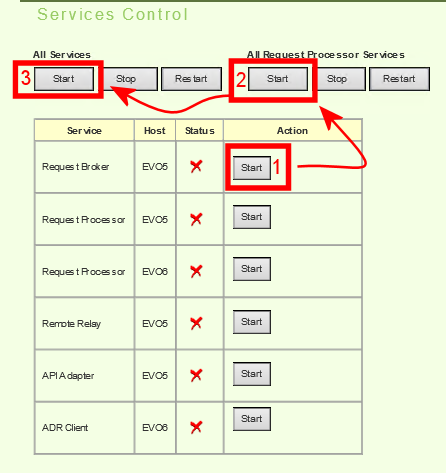
Important: the order of starting Evolution services must be:
It appears that the Request Broker simply needs to get fully started and settled into place before the other services start and phone home. If this start order is not respected, I believe that the Broker and Request Processors get out of sync with each other and fail to communicate properly.
When this out-of-sync thing happens, Evolution appears to be running properly from the view of the Evo Mgmt Console and the system administrator, but Evolution users see a locked up environment.
This is most painful when the admin performs maintenance in the off hours, but Evo users don't trip across it until business hours the following morning. A full and proper (and interruptive) restart is required to fix this.
We have no real sense for what's the root cause of this issue, but it happens often enough (let's say 25% of the time), that as a matter of practice I always start in the proper order. Classic SaaS pod orchestration enforces this start order also.
A note about the third step: starting all the other services—Remote Relay, API Adapter, and the ADR Service— you can use the [Start] in "All Services". This button is smart enough to not touch services that are already running
Some customers, when doing their own maintenance, use the individual [Start] buttons on each service and start each one in order, from top to bottom. This works reliably also.
Sometimes to clear up an Evolution stuck condition, you decide (or are told by Support) to restart Evolution services. As noted above, never ever click the [Restart] button in the Evo Mgmt Console; it's simply not reliable and should never be used.
Therefore, when one needs to restart all Evo services, you perform a proper stop followed by a proper start as noted in the previous sections, but the steps can be summarized as:
The above scenarios—starting, stopping, and restarting—all presume that the underlying Windows machines stay running the whole time, but all systems undergo maintenance such as applying Windows Updates. This involves rebooting the systems in question, and special procedures must be employed to make sure Evo starts properly.
Even if Evolution is fully stopped properly prior to rebooting, the services all come up in their own random order: this is essentially a [Start] All Services, and it often leads to Evo hangups requiring a proper restart.
There are two approaches to handle this:
For those of a scripting bent, it's easy to automate some of this with PowerShell: I've been using a Set-EvoRBSTartup.ps1 script to manage the startup state when performing maintenance at my customers.
First published: 2018/10/05


![Click [Stop] in All Services](../images/emc-services-stop-all.png)
![[Steve's Email]](/images/steve-email.gif)