This site uses advanced css techniques
Most of us who've spent any time in the Evo Management Console have looked at the Server Monitor page and noticed the scores of the various servers, and perhaps wondered just exactly what they mean.
This paper describes how the score is to be understood, and how Evolution uses it to decided which server the next job goes on. In addition, understanding why a large disparity in machine scores leads to the surprising result that fewer machines can result in better Evo performans.
This was written as of the Norwich release.
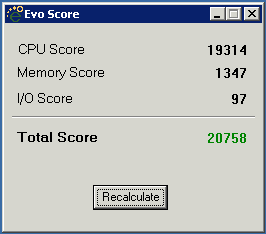 The "Score" is Evolution's internal tally of just how beefy a machine is, and it's a dimensionless number
(i.e., has no units of measure). It's built upon factors of CPU speed and number of cores, how much RAM,
and I/O capacity.
The "Score" is Evolution's internal tally of just how beefy a machine is, and it's a dimensionless number
(i.e., has no units of measure). It's built upon factors of CPU speed and number of cores, how much RAM,
and I/O capacity.
In 2011, iSystems published a utility EvoScore that exposes a bit of the algorithm used to compute the score. When run on a server, it shows the components that go into the final score shown in the Management Console, and a representative screenshot is shown to the right.
The bottom-line score is more familiarly seen in the Evo Management Console when in the Server Monitor section:
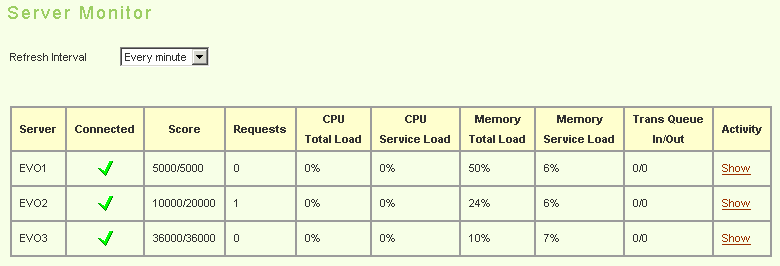
The Management Console and EvoScore use the same algorithm internally, though the score does flucutate a bit due to other activity on the system in question (if it's busy spooling a print job, for instance, it might lower the apparent score a bit).
I don't know just exactly how they arrive at these numbers, but the general idea is, as with many other things, bigger is better.
The EvoScore utility, though interesting, is of fairly limited value in practice. The final score is always available from the Management Console, and it's probably only really useful when running on an existing server being considered for use in the middle tier. You'd never need to run it on a new server, because new servers are always fast servers.
Perhaps as the Evo community gets more experience understanding not just the final score, but the parts that go into it, we'll be able to use this breakdown to make better decisions.
A key part of the Request Broker is the scheduling algorithm, which decides which Request Processor will be assigned a new task initiated by the user. Its job is to spread the load around and to keep all the servers more or less equally busy, but as we'll see, sometimes it's not always able to attain that goal.
Note that this description is oversimplified a bit, quietly disregarding finer points such as the difference between a realtime tasks and a queue tasks, as well as the differences in multiclient reports are handled. But it will nevertheless serve to illustrate the concepts generally.
In addition to a score, each Request Processor has a CPU count, which counts the number of CPU cores available. The Evo scheduler will never assign more tasks than the number of available cores, so (for instance) a four-core machine will never have four jobs running at once.
This means that the total number of payroll tasks that can run at one time is the total of all available CPU cores, and when users request more than that, a "Waiting for resources" condition arises.
So, the Evo scheduler has a list of available Request Processors, each with a score and a # of CPU slots. The score is actually split into two parts: a "maximum score", and an "available score".
Revisiting the Server Monitor screenshot above, you can see the two numbers in the Score column: the first is the available score, while the second is the maximum score. The maximum score is fixed and won't change while Evo is running, but that's not used for scheduling.
Instead, only the available score is used for scheduling.
When the Request Broker wishes to assign a task, it takes these steps:
The effect is that as Request Processors get more work, their lowered available scores make them less attractive for future scheduling, allowing the work to be spread around across all the Request Processors machines.
As well, when a task finishes on an RP, the CPU slot is freed up and the available score doubled, making it more attractive for receiving work.
This scheduling algorithm has been in place since Lincoln.
Though the above algorithm does spread the load around in any case, when there is a wide disparity in scores from slowest to fastest, the scheduler will disproporationately penalize the faster machines after just a few jobs, putting tasks on slower machines that nevertheless have higher scores.
To see the effect of this, I wrote a simulator that takes the parameters of a set of middle tier servers and shows how jobs are allocated across them as the machine gets busier and busier.
In this simulator output for our set of three machines, it shows the effect of adding each of 36 tasks, and which machine received it. In each column, it shows the machine name and the running available score and available CPU slots, each being reduced as jobs are placed on them. It highlights which server received each task with **:
Servers:
EVO1 4 CPUs 5000 score
EVO2 8 CPUs 20000 score
EVO3 24 CPUs 36000 score
EVO1 EVO2 EVO3
STARTING SCORE 5000/4 20000/8 36000/24
Add task # 1 5000/0 20000/0 18000/1 ** assign to EVO3
Add task # 2 5000/0 10000/1 ** 18000/1 assign to EVO2
Add task # 3 5000/0 10000/1 9000/2 ** assign to EVO3
Add task # 4 5000/0 5000/2 ** 9000/2 assign to EVO2
Add task # 5 5000/0 5000/2 4500/3 ** assign to EVO3
Add task # 6 2500/1 ** 5000/2 4500/3 assign to EVO1
Add task # 7 2500/1 2500/3 ** 4500/3 assign to EVO2
Add task # 8 2500/1 2500/3 2250/4 ** assign to EVO3
Add task # 9 1250/2 ** 2500/3 2250/4 assign to EVO1
Add task # 10 1250/2 1250/4 ** 2250/4 assign to EVO2
Add task # 11 1250/2 1250/4 1125/5 ** assign to EVO3
Add task # 12 625/3 ** 1250/4 1125/5 assign to EVO1
Add task # 13 625/3 625/5 ** 1125/5 assign to EVO2
Add task # 14 625/3 625/5 562/6 ** assign to EVO3
Add task # 15 312/4 ** 625/5 562/6 assign to EVO1
Add task # 16 312/4 312/6 ** 562/6 assign to EVO2
Add task # 17 312/4 312/6 281/7 ** assign to EVO3
Add task # 18 312/4 156/7 ** 281/7 assign to EVO2
Add task # 19 312/4 156/7 140/8 ** assign to EVO3
Add task # 20 312/4 78/8 ** 140/8 assign to EVO2
Add task # 21 312/4 78/8 70/9 ** assign to EVO3
Add task # 22 312/4 78/8 35/10 ** assign to EVO3
Add task # 23 312/4 78/8 17/11 ** assign to EVO3
Add task # 24 312/4 78/8 8/12 ** assign to EVO3
Add task # 25 312/4 78/8 4/13 ** assign to EVO3
Add task # 26 312/4 78/8 2/14 ** assign to EVO3
Add task # 27 312/4 78/8 1/15 ** assign to EVO3
Add task # 28 312/4 78/8 0/16 ** assign to EVO3
Add task # 29 312/4 78/8 0/17 ** assign to EVO3
Add task # 30 312/4 78/8 0/18 ** assign to EVO3
Add task # 31 312/4 78/8 0/19 ** assign to EVO3
Add task # 32 312/4 78/8 0/20 ** assign to EVO3
Add task # 33 312/4 78/8 0/21 ** assign to EVO3
Add task # 34 312/4 78/8 0/22 ** assign to EVO3
Add task # 35 312/4 78/8 0/23 ** assign to EVO3
Add task # 36 312/4 78/8 0/24 ** assign to EVO3
The first task, of course, was assigned to the fastest machine, EVO3, but its 36000 score was then cut in half, making EVO2 the fastest available machine for the second task. This process repeats as more and more are allocated, and finally after 36 tasks the system is full. At this point, the next task would receive a "Waiting for resources" message.
It's here where we can start to ask some questions about whether this is really the best way to divvy up the jobs. The machine EVO3, which is very fast, is only given three tasks before EVO1 gets one. There's the rub.
In this case, I believe that the EVO3 machine is so fast, that even while running three tasks, it's still going to outperform EVO1 with just a single tasks. This is in some respects a reflection of just how powerful modern machines are, that old ones are simply not able to contribute all that much.
This begs the question: is it really even worth having EVO1 around at all?
Given this scheduling algorithm, I believe the answer is no, at least not in the production Evolution instance.
If we were to remove EVO1 entirely, we can see how the scheduler will divide up the requests among the remaining two machines:
Servers:
EVO3 24 CPUs 36000 score
EVO2 8 CPUs 20000 score
EVO2 EVO3
STARTING SCORE 20000/8 36000/24
Add task # 1 20000/0 18000/1 ** assign to EVO3
Add task # 2 10000/1 ** 18000/1 assign to EVO2
Add task # 3 10000/1 9000/2 ** assign to EVO3
Add task # 4 5000/2 ** 9000/2 assign to EVO2
Add task # 5 5000/2 4500/3 ** assign to EVO3
Add task # 6 2500/3 ** 4500/3 assign to EVO2
Add task # 7 2500/3 2250/4 ** assign to EVO3
Add task # 8 1250/4 ** 2250/4 assign to EVO2
Add task # 9 1250/4 1125/5 ** assign to EVO3
Add task # 10 625/5 ** 1125/5 assign to EVO2
Add task # 11 625/5 562/6 ** assign to EVO3
Add task # 12 312/6 ** 562/6 assign to EVO2
Add task # 13 312/6 281/7 ** assign to EVO3
Add task # 14 156/7 ** 281/7 assign to EVO2
Add task # 15 156/7 140/8 ** assign to EVO3
Add task # 16 78/8 ** 140/8 assign to EVO2
Add task # 17 78/8 70/9 ** assign to EVO3
Add task # 18 78/8 35/10 ** assign to EVO3
Add task # 19 78/8 17/11 ** assign to EVO3
Add task # 20 78/8 8/12 ** assign to EVO3
Add task # 21 78/8 4/13 ** assign to EVO3
Add task # 22 78/8 2/14 ** assign to EVO3
Add task # 23 78/8 1/15 ** assign to EVO3
Add task # 24 78/8 0/16 ** assign to EVO3
Add task # 25 78/8 0/17 ** assign to EVO3
Add task # 26 78/8 0/18 ** assign to EVO3
Add task # 27 78/8 0/19 ** assign to EVO3
Add task # 28 78/8 0/20 ** assign to EVO3
Add task # 29 78/8 0/21 ** assign to EVO3
Add task # 30 78/8 0/22 ** assign to EVO3
Add task # 31 78/8 0/23 ** assign to EVO3
Add task # 32 78/8 0/24 ** assign to EVO3
This appears to be quite a bit more equitable, and though there are four less requests serviced overall, they'll get handled more quickly without the slow machine involved, and this will likely provide a more responsive Evo environment.
This is not to say that machines like EVO1 have no value; a score of 5000 is still plenty useful, and the difficulties above are more due to the scheduling algorithm rather than to any inherent defect.
There are a number of ways that such a machine could be put to good use:
Note: for doing your own hotsite, a single machine like this is probably not going to do the trick even with a reasonable score of 5000 because of the limit of only 4 CPU slots. In this environment, "Waiting for resources" would be a chronic problem. Adding a second machine similar to the first might make this usable.
A test Evo instance would not suffer from the same plight, as they're not typically subjected to full payroll loads.
To illustrate how a pair of 5000-score machines would operate, I've run the simulator again with a hypothetical EVO4, with the same specs:
Servers:
EVO1 4 CPUs 5000 score
EVO4 4 CPUs 5000 score
EVO1 EVO4
STARTING SCORE 5000/4 5000/4
Add task # 1 2500/1 ** 5000/0 assign to EVO1
Add task # 2 2500/1 2500/1 ** assign to EVO4
Add task # 3 1250/2 ** 2500/1 assign to EVO1
Add task # 4 1250/2 1250/2 ** assign to EVO4
Add task # 5 625/3 ** 1250/2 assign to EVO1
Add task # 6 625/3 625/3 ** assign to EVO4
Add task # 7 312/4 ** 625/3 assign to EVO1
Add task # 8 312/4 312/4 ** assign to EVO4
Here we see that the scheduler exactly balances the load across both machines; this even-ness works for as many machines as you like, for any score, as long as all have the same score.
It seems clear to most of us who've studied this that the current algorithm used by the scheduler doesn't work very well when there is a wide disparity in performance, as it overemphasizes the power of the slower machine, slowing Evo down overall.
Surely there's a way to incorporate these older machines, assigning them work only after the faster machines have gotten truly busy, but this is a much trickier problem than it looks.
One approach might be to devalue the score less on each job: perhaps only a 25% reduction for each task rather than the current 50% reduction. Using this factor in the simulator, EVO1 would not be assigned work until task #13, rather than #6 in the current mechanism. This is promising.
Another approach might reduce the score proportionally to the number of CPUs; for EVO3, each task might reduce the available score by (1/24) * 36000 = 1500, reflecting that each task is taking just 1/24th of the system's resources.
But this means that EVO3 gets ten jobs before EVO2 gets its first, and this is probably not dividing up the load all that well even though it does put the slower EVO1 at the bottom of the list.
This illustrates that even plausible algorithms can have surprises or corner cases that don't work very well, meaning that one does not change these algorithms lightly.
So, for now, the best approach is to limit the disparity between machine scores in the middle tier, retiring older machines as needed and bringing in newer machines to even the score.
First published: 2011/09/07
![[Steve's Email]](/images/steve-email.gif)